
Build Better Products Through Systems Thinking
Three Core Systems Thinking Principles For Product Engineers

Even a small change can have unintended ripple effects, breaking functionalities in areas that aren’t even considered related.
We are often focused on the immediate task and miss the bigger picture until circumstances remind us again of a valuable lesson: in software development, everything is connected, and ignoring that interconnectedness can lead to a disaster.
Enter systems thinking—a way of looking at the whole rather than just the parts. To build robust, reliable software, we must understand how pieces fit together, anticipate the unexpected, and continuously learn from our outcomes.
Discover how a product engineering mindset can future-proof your career and bring deeper satisfaction to your work. Subscribe to Enginuity for practical guidance delivered straight to your inbox.
The Butterfly Effect in Systems
We often focus intensely on the immediate problem at hand. We're eager to add that new feature, fix that bug, or push that release. But in this haste, we sometimes overlook how a small change can cascade through the system, leading to unintended consequences that can be costly or even catastrophic.
Anticipating and being on the lookout for these consequences helps avoid the costly cycle of fixing problems after they've been deployed. The bottom line is that users expect software to work reliably. Frequent bugs or downtime can damage a product’s reputation and lead users to seek alternatives.
Unintended consequences are often the result of not seeing the forest for the trees. We need to step back and consider the wider impact of our work.
Let’s look into two common system-thinking mistakes and then discuss a simple strategy to promote preemptive anticipation of such ripple effects.
Mistake 1: Ignoring the Bigger Picture
Individual software components rarely function in isolation. They are part of a larger ecosystem where each element influences and is influenced by others. This interconnectedness means we must think beyond the immediate scope and consider the broader impact of our work.
The impact of interconnectedness within the system is often revealed in later stages of development or only after the system is released and integrated within the production environment:
Hidden Dependencies: Modifying an API without realizing other modules rely on it.
Integration Problems: New code might work perfectly in isolation but cause issues when integrated with other components.
User Experience Impacts: A backend change that slows down response times can frustrate users, even if the change was meant to improve functionality.
Resource Constraints: Ignoring how a new feature might consume memory, CPU, or network bandwidth can degrade overall performance.
Mistake 2: Assuming the Happy Path
We often write code assuming everything will go as planned—the user provides valid input, the network is reliable, and resources are plentiful. But real-world conditions are messy.
Engineers often refer to conditions that are not on the assumed “happy path” as edge cases. The name itself holds the assumption that the probability of the occurrence of such an event is low, which is generally an incorrect assumption. You can only make such a statement after you confirm it via production telemetry over a long period of time. Failing to handle “edge cases” can lead to system failures, race conditions, and data corruption.
A popular scenario of unhandled edge cases is assumed inputs—not validating user or API inputs, leading to security vulnerabilities or system crashes when unexpected data is processed.
Scenario Planning with "What If?" questions
One of the most powerful tools in anticipating unintended consequences is scenario planning. Start by mapping out how your software is intended to work and what different scenarios a user can encounter. Then, deliberately consider how it might fail. Sometimes, this practice is called pre-mortem (as opposed to post-mortem). For example:
User Behavior: What if users input unexpected data? What if they click buttons in an unforeseen order?
System Failures: What if the database goes down? What if the network is slow or unreliable?
External Dependencies: What if a third-party API changes or becomes unavailable?
Security Threats: What if someone tries to hack into the system?
“What if” questions help you see the bigger picture, analyze the potential impact, and develop mitigation strategies for the highest-priority scenarios.
The Case Against Oversimplification
In the rush to deliver, it's tempting to boil down complex problems into simple solutions. We tell ourselves that by simplifying and overlooking nuances, we'll move faster and more efficiently.

But oversimplification often comes at a steep price. When we cut corners to make a problem seem easier, we lose critical information. As the saying goes: “The devil is in the details.” Ignoring them can lead to solutions undermining all sides of the Value - Quality - Time triangle:
Value: Oversimplification can lead to a flawed product design. If we don't understand user needs, we risk building something that doesn't solve the right problem.
Quality: Avoiding the inherent system complexity results in architectural tech debt. As the system grows, the ignored debt resurfaces, making the codebase harder to maintain and evolve. This debt is often paid with high interest. Future changes become more costly and time-consuming, slowing down progress and innovation.
Time: Underestimating the complexity of a task leads to unrealistic timelines and resource allocation. Projects overrun their deadlines, budgets grow, and teams burn out. As a result, such projects often move much slower than well-estimated ones and lose the trust of stakeholders.
How To Use Complexity Effectively
Ask the Right Questions: Probing into the difficult aspects of a problem can save you a lot of future efforts for overhauling your overall solution. Try asking:
What dependencies exist?
What are the edge cases?
How might the system evolve?
How can risks of possible future issues be minimized?
Iterate Thoughtfully. The goal is to break down the complexity into smaller, manageable pieces. This is different from oversimplifying, which avoids addressing many of those pieces from the very beginning. Tackle each piece methodically, ensuring it fits into the larger picture.
Invest in Good Design: Take architectural decisions that favor flexibility and scalability. I cannot stress this enough! If your system is extendable and maintainable, you are on a great path. This investment pays off by reducing future work and technical debt.
Be Honest in Estimates: When planning, factor in the complexities. It's easy to be a “yes-man” and underestimate the work ahead, but in the end, stakeholders prefer realistic timelines over unreachable ones.
Applying Feedback Loops
Feedback loops are the mechanisms for learning and adaptation. Because of them, we know whether what we're doing is working or not, and without them, we're just guessing.
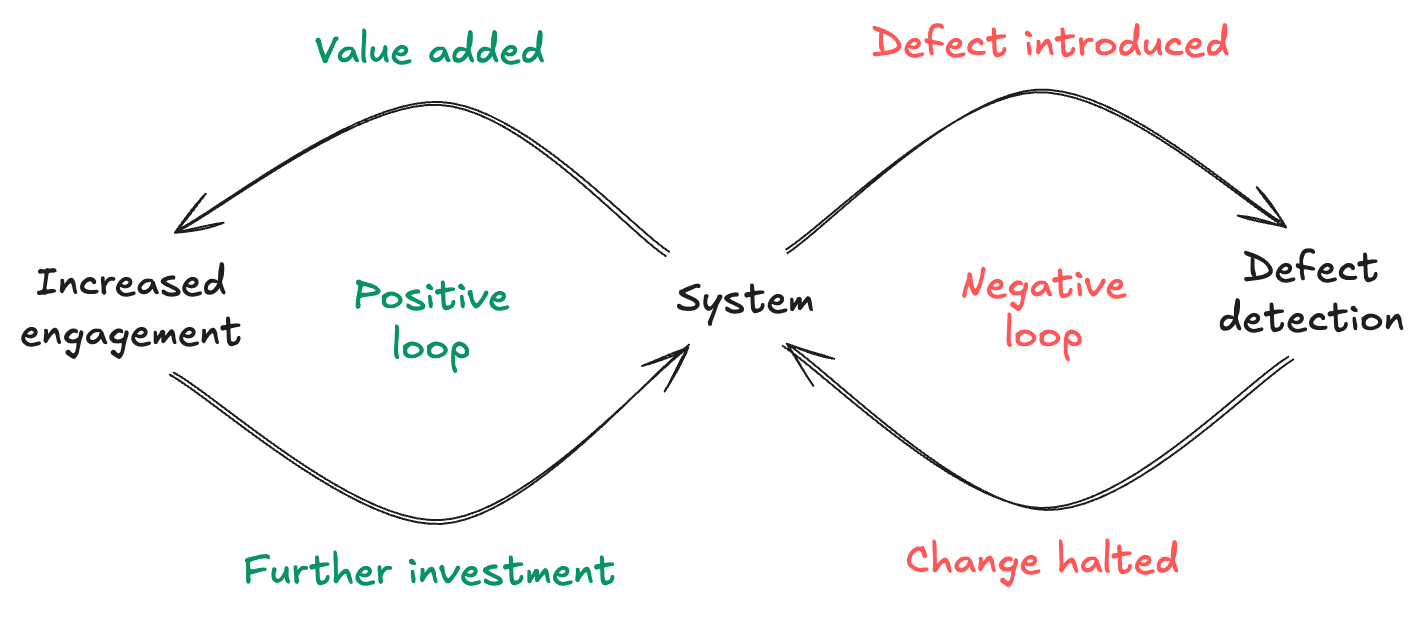
Positive feedback loops reinforce a particular behavior and lead to its amplification, for example:
Feature Adoption: A new feature that gives users a lot of value leads to increased usage, encouraging further investment in that area.
Code Quality Improvements: Refactoring code makes it easier to add new features, which leads to more refactoring also in other areas because the benefits are clear.
Negative feedback loops counteract changes and promote stability and balance. Examples:
Automated Testing: Failing tests signal issues that need fixing before code is merged, preventing bugs from reaching production.
Continuous Integration (CI): Build and integration failures alert the team to problems and incompatibilities early, avoiding bigger production problems later.
Mistake 1: Delayed Feedback
Delaying feedback usually means ignoring negative feedback loops.
One example is the use of long-running feature branches. They often accumulate and batch many changes before testing or deploying, which delays feedback and makes it harder to pinpoint issues. Another variant is infrequent batched releases, where teams merge their changes to the main branch, but the production release itself happens only a few times a year.

Another common mistake is ignoring test failures. As we move up the testing pyramid, the probability of tests being flaky increases because more systems are included in the tests. Proceeding despite failing tests undermines the purpose of testing. Of course, the worst scenario is not writing or running tests at all.
Prevention:
Automated CI/CD: Automating testing and deployment ensures that test suites are run consistently and deployments to all environments are repeatable and reliable.
Fail Fast: Early detection mechanisms, such as unit tests, type checks, linting, and code coverage, prevent issues from snowballing into bigger problems.
At the same time, knowing that tests have your back makes it safer to improve the codebase and refactor with confidence.
Code Reviews: Reviewing the code before it’s committed to the main releasable branch is one of the most effective ways to prevent architectural tech debt and avoid changes that decrease the system's maintainability.
Mistake 2: Low-Value Feedback
First, let’s address the "no feedback” scenario. Without monitoring or observability in your production system, you won’t know when and why things break. Long outages damage product reputations and cause user dissatisfaction and churn.
Low-value feedback is feedback collected without a proper strategy, prioritization, and categorization of its sources. For example, tracking too many metrics can obscure what's important. It can desensitize the team to the data arriving from the system, causing important signals to be missed.
One of the worst-case scenarios is when these low-value or limited feedback loops drive drastic product course corrections. Such knee-jerk reactions result in long-term instability and loss of product’s identity.
Prevention
Prevention strategies, in this case, are focused on identifying high-value positive feedback loops:
Feature Prioritization: Instead of having dozens of different metrics and statistics, focus on having a few high-value composite metrics coming from validated sources. You can create valuable insights only when you trust the data coming from the system.
User Behavior Tracking: Understand how users interact with your software to make informed decisions. Just because two things happen together doesn't mean one caused the other. Be cautious when drawing conclusions. Check out Michał Poczwardowski’s article Correlation Does Not Imply Causation.
Summary
Let’s sum up the three principles:
Consider the interconnectedness of components to avoid the butterfly effect, in which small changes ripple through the system and cause damage.
Employ scenario planning with "What If?" questions to discover the real radius and impact of the change.
Avoid oversimplification, which leads to loss of critical information, and instead use complexity effectively through exploration, good architectural design, and iteration.
Leverage positive feedback loops to achieve amplification of valuable outcomes and negative feedback loops to prevent harmful changes from destabilizing your system.
📖 Read Next
Discover more from the Product Engineering track:
Overcoming Career Plateaus

If you’re like me, your engineering career started in the spirit of strong motivation, high expectations, and endless energy for delivering new projects.

If you’re looking for a space where you can learn more about software engineering, leadership, and the creator economy, with Dariusz Sadowski, Michał Poczwardowski, and Yordan Ivanov 📈, we’ve created the Engineering & Leadership discord community:
📣 Top Picks
The one framework every engineer should know by Jordan Cutler and Torsten Walbaum in High Growth Engineer
Safe vs ALL-IN Engineering Management by Anton Zaides in Leading Developers
Code Quality in the Age of AI by Luca Rossi and Cédric Teyton in Refactoring
Samuel, I really enjoyed this article.
System thinking for me means involving developers very early in the product development process and keeping them in the loop.
Only if you understand your domain and the product’s users well you can think holistically on the impact of your work on their experience.
Nice one 👌🏼