
Overcoming the 8 Fallacies of Distributed Computing
A Practical Guide for Microservices Excellence

Distributed systems introduced new challenges and misconceptions — commonly known as the "Fallacies of Distributed Computing."
Initially outlined by L. Peter Deutsch and others at Sun Microsystems, these fallacies are the incorrect assumptions developers might make about distributed computing environments. Even though they are decades old, their relevance has only been magnified with cloud computing and IoT.
Understanding these fallacies is a practical necessity. In the realm of microservices, these misconceptions can have a significant impact. Issues like network latency, security vulnerabilities, and resource limitations can cascade through the system, lowering applications' reliability, performance, and scalability.
This article offers a path forward through practical examples and remedies for these misconceptions.
1. The Network is Reliable 🛜
The belief that network communication is reliable and without faults can lead to many problems in distributed systems. This optimistic view overlooks the unpredictability and complexity of network operations. The reality is that networks can and do fail, whether due to hardware malfunctions, congestion, or external disruptions.

Remedy
There are several resiliency patterns to mitigate the impact of unreliable networks:
Retry logic with exponential backoff — A service attempts reconnections to another service, but with progressively longer waits between retries (500ms, 1s, 5s, 10s, …) to avoid overwhelming the network or the service.
Circuit breaker pattern — Prevent a service from trying to perform an operation that's likely to fail. For example, after failing to call another service five times a row, the circuit breaker will no longer call the service and immediately return an error. This gives the failing service time to recover and maintains system stability.
Message queues — An intermediary layer between services, allowing messages to be stored temporarily until the receiving service can safely process them. In the event of network failure, messages are stored in the queue. The stored messages can be replayed once the network is restored or the receiving service is online.
2. Latency is Zero 🚀
A misleading assumption in distributed systems is that network communication occurs with zero latency. This assumption disregards distances data must travel, infrastructure limitations, and physics itself. In microservices architectures, ignoring latency can lead to inefficient designs and poor UX as operations become bottlenecked by waiting for responses.
Remedy
Asynchronous programming — This approach allows a process to call another service and proceed with the execution of other tasks without waiting for the response, thus not blocking other operations.
Caching mechanisms — Caching can also drastically reduce latency by storing frequently accessed data closer to where it's needed, minimizing the need for repetitive, time-consuming calls across the network.
Autonomous services — Right-sized services owning domain logic help reduce communication dependencies and can further minimize latency impacts.
3. Bandwidth is Infinite 🚅
The assumption that bandwidth is limitless is a common oversight in the design of distributed systems. This fallacy leads to flawed architecture, especially in high-traffic or data-intensive operations. In reality, bandwidth constraints lead to bottlenecks and service degradation as applications compete for network resources.

Remedy
Data compression — This technique can significantly reduce the data size that has to be transferred, requiring less bandwidth and improving transmission time. Compression algorithms can be applied to all kinds of data types, including text, images, and video, making this a versatile solution.
Throttling — Another technique for effectively managing bandwidth usage. By limiting the rate at which data is sent or received, throttling helps prevent any single client or service from consuming too much bandwidth, ensuring a more fair distribution of network resources.
Scaling — By designing systems to dynamically add resources across the globe (instances, nodes, processes, etc.) in response to increased demand, it's possible to accommodate traffic surges without exceeding bandwidth limits. This approach not only addresses bandwidth constraints but also improves the overall scalability and resilience of the system.
4. The Network is Secure 🔒
The network environment is inherently insecure against unauthorized access and cyber-attacks. The opposite assumption can lead to forgetting to implement robust security measures and underestimating cyber threats. The reality is that as microservices increase in complexity, their potential security vulnerabilities also increase. This makes them targets for attackers looking to exploit weaknesses in network communication.
Remedy
There is a large body of work done on this topic, and the most we can do here is scratch the surface, but let’s mention these strategies:
TLS for Secure Communication — Transport Layer Security (TLS) ensures that data transmitted between services is encrypted, making it difficult for attackers to intercept and decipher. Implementing TLS is a fundamental step in protecting data in transit.
Zero Trust — This security model operates on the principle that no entity should be automatically trusted, whether inside or outside the network perimeter. Access requests must be fully authenticated, authorized, and encrypted before communication can proceed. This approach is very effective in distributed systems where services are spread across different environments and networks.
Vulnerability Assessments — Continuous monitoring and regular vulnerability assessments are critical in identifying and mitigating potential security threats. Penetration testing and security audits can maintain strong security against cyber threats. Applying security patches and regularly updating security protocols is another best practice.
5. Topology Doesn't Change 🧭
The network's structure and configuration are not static entities. Failing to accommodate the dynamic nature of the cloud, where changes in topology are common, can lead to rigid architecture. Factors such as resource scaling, failovers, or service migrations contribute to such changes.
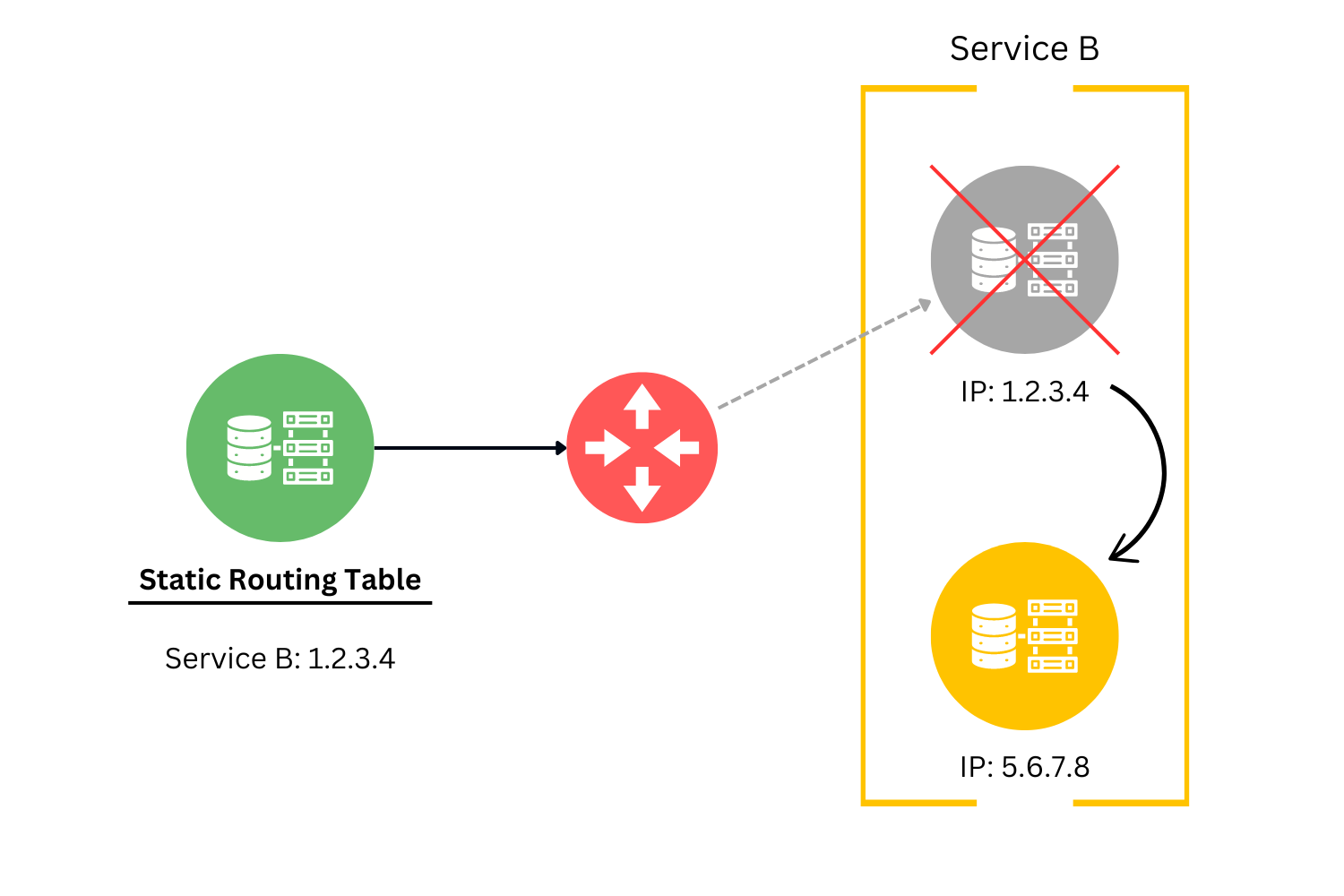
Remedy
Service Discovery Mechanisms: Service discovery allows services to dynamically locate other services and communicate with each other even when network changes occur. By registering services with a discovery tool (e.g., Consul or Zookeeper), applications can query for the current network locations of other services, abstracting away the specifics of network addresses and ports.
Dynamic Routing: Dynamic routing protocols ensure that traffic can be dynamically rerouted to accommodate network changes. In microservices architectures, API gateways or service meshes can manage routing rules, directing requests to the correct service instances based on their current availability and network location.
6. There is One Administrator 🧑💻
This simplification overlooks the complex reality of modern software and hardware environments, where different teams manage various components. Each can have their unique processes, tools, and responsibilities. This diversity can lead to inconsistent configurations, policies that are too permissive, and missing security practices, which can create significant challenges.
Remedy
Centralized Governance: Establishing this model ensures that shared policies, security standards, and compliance requirements are uniformly applied across all services, regardless of the team managing them. This governance should define clear guidelines for configuration management, service deployment, and security protocols.
Infrastructure as Code (IaC): While governance remains centralized, the execution of these policies should be decentralized. Individual teams should have autonomy to manage their services within these guidelines. Utilizing IaC tools like Terraform or CloudFormation enables teams to automate and standardize service configurations across different environments. This also reduces manual errors and makes deployment processes easier and less risky.
7. Transport Cost is Zero 💰
This assumption is that data transportation across the network is cost-free. This can lead to applications that are not optimized for the financial and performance costs associated with data transfer. The costs of moving data, especially in cloud environments, can be significant.
Remedy
Self-Contained Services: Encapsulating both the business logic and the data, each service can perform its functions with minimal external data dependencies. Cross-cloud dependencies usually infer higher costs for data transfer. This autonomy decreases network traffic and increases the system's resiliency.
Data Localization: Implementing data localization strategies involves deploying services and their corresponding data closer to where they are consumed or where the data is generated. This can mean choosing cloud regions based on user demographics or using edge computing. Data localization reduces the distance data must travel, lowering transfer costs and improving application performance.
8. The Network is Homogeneous 🌐
The network environment in which distributed systems operate is not uniform across all nodes.
Modern distributed systems run in cloud, on-premises data centers, edge computing environments, and hybrid setups. These systems have different network configurations, protocols, and infrastructure components. Forgetting this can result in compatibility issues, performance bottlenecks, and increased complexity in managing cross-environment communication.
Remedy
Containerization and Orchestration Tools: Containerization technologies, such as Docker, allow for packaging services along with their dependencies, ensuring consistent execution environments. Orchestration tools like Kubernetes help manage these containers and facilitate service discovery, load balancing, and automatic scaling. This abstracts away the complexity of the underlying network, providing a unified platform for deploying and scaling services across various environments.
Environment Consistency: Infrastructure as Code (IaC) and CI/CD pipelines ensure consistent development and production environments. This reduces discrepancies in network environments and the risk of environment-specific failures.
In Case You Missed It
In the last issue, we discussed how the CAP theorem influences the design of distributed systems, SQL and NoSQL databases, and how Blockchain challenges its structure.
The CAP Theorem: The Backbone of Distributed Systems

The CAP Theorem, a core principle of distributed systems, states that in the presence of a network partition, a distributed system can provide either consistency or availability, but not both. In other words, a distributed system can only provide two of three properties simultaneously:
Top picks this week
How to manage up as an engineer or a manager in Engineering Leadership by Gregor Ojstersek
GenZ software engineers, according to older colleagues in The Pragmatic Engineer by Gergely Orosz
How to Self-Manage Even if You Have a Manager in The Caring Techie Newsletter by Irina Stanescu
i chuckled reading “ network is reliable”