
Demystifying AI: The Age-Old Math Behind Today's Machine Learning
The Continuing Legacy of Stochastic Gradient Descent in Modern Deep Learning

In the bustling world of artificial intelligence, one mathematical concept plays the role of an unsung hero. Much like the foundation of a skyscraper, it remains invisible yet indispensable. This hero is none other than Gradient Descent, a cornerstone algorithm that drives the learning process in most modern deep-learning systems.
Its story begins in the mid-19th century, when the concept of gradient descent, the precursor to stochastic gradient descent, was born from the quest to help solve mathematical problems in Astronomy. The year 1951 introduced the earliest stochastic approximation methods, and in 1986, backpropagation was first described, with stochastic gradient descent being used to efficiently optimize parameters across neural networks.
But don't worry. You don't need a PhD in mathematics to understand how it works. Let's dive into this intriguing world, breaking down complex ideas into digestible, everyday language.
The Quest for Perfection
Imagine you're learning archery. Each shot you take is an attempt, and the distance between your arrow and the bullseye represents your error. In machine learning, a function that represents the calculation of the overall error is called the Loss Function. It calculates the “distance” between the AI's predictions and the true outcomes. We aim to adjust the AI's parameters so this distance, or loss, is as small as possible — turning a novice archer into a skilled marksman.

Stochastic Gradient Descent (SGD) comes into play as AI’s instructor, guiding its practice shots to improve accuracy. In each iteration, SGD slightly tweaks the model's parameters, aiming to reduce the loss. This tweaking of parameters to minimize the overall loss is what we call “learning”. Going through the learning process, an AI model is able to perform the task in a more and more accurate way, whether it is recognizing images of cats or generating a new Shakespearean poem.
Understanding the Gradient: The Slope of Learning
Before we tackle the Stochastic Gradient Descent, let's clarify what a “gradient” is.
In the simplest terms, the gradient is a fancy word for “slope”. Imagine you're hiking on a hilly terrain. The gradient simply tells you how steep the hill is at any point.

Mathematical Foundations (Optional)
Without going too deep into Differential Calculus, we can say that for a function f(x,y,…,z) with multiple variables, the gradient is the collection of all its partial derivatives. Each partial derivative represents the rate of change of the function with respect to one variable, holding other variables constant.
Mathematically, if our function is f(x,y), which is a function with two parameters, x and y, the gradient ∇f is:
This might look intimidating, but let's break it down. If our function f represents the error in our machine learning model, the partial derivative ∂f/∂x tells us how the error changes as we tweak parameter x and similarly, derivative ∂f/∂y tells us how the error changes as we tweak parameter y.
If you remember the section above, tweaking parameters to minimize the overall error is precisely what represents the “learning” in the Deep Learning models.
In the context of machine learning, think of the gradient as a measure of loss for our defined Loss function. It points in the direction where the loss is increasing fastest.
Descending the Gradient: Learning Step-by-Step
By moving opposite to the direction of the gradient (that is, opposite to the direction of the steepest growth of the error), we aim to reduce the error, similar to how you'd want to hike downhill to exert less effort.
This is exactly what gradient descent does. It acts as a hiker trying to find the lowest point in a vast valley (our error landscape). Each step it takes is guided by the steepest path downhill, representing the most efficient way to reduce error in our model's predictions.
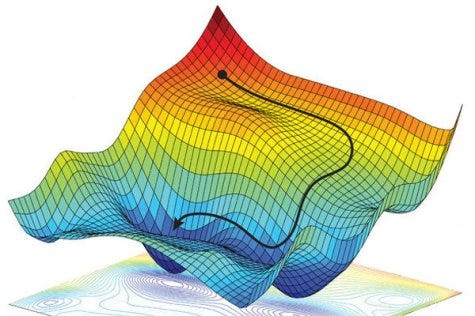
By moving in the opposite direction of the gradient, we seek the point where the error is minimized—our model's best performance. This is the heart of gradient descent: use the gradient to guide your steps in the parameter space until you find the lowest point, the (locally) optimal solution.
Mathematical Foundations (Optional)
In this more advanced section, let’s look into the mathematical underpinnings of gradient descent, specifically its role in minimizing a loss function (sometimes also called cost function).
This function measures how well our model performs. It calculates the difference between the model's predictions and the actual data. In the archery example above, the closer you are to the bullseye, the lower your loss is.
Let’s use one of the most common regression functions — Mean Squared Error. Mathematically, if our predictions are denoted by ŷ (read as "y-hat") and the actual values are y, the loss function looks like this:
θ are parameters we want to optimize
L(θ) represents the loss function dependent on parameters θ
n is the number of data points
The goal of gradient descent is to minimize this loss function, essentially finding the set of parameters θ that result in the lowest possible loss.
The algorithm starts with random parameters (a random spot on the hill) and incrementally updates them in the opposite direction of the gradient of the loss function at that point (the downhill direction):
As we can see, new θ parameters are calculated based on the old θ parameters. The update is done based on the gradient ∇ of the loss function L(θ). The minus sign ensures we move in the opposite direction of the gradient.
You might notice there is a new parameter present — α, which represents the learning rate. α defines how much we want the value of the gradient to influence the new value of parameters θ. Having the learning rate too high might mean that the algorithm makes too big steps and might overstep a local minimum. On the other hand, having a low learning rate might result in slow learning, so either having low performance or never finding the minimum. Many libraries use default learning rates of 0.01 or 0.001.
Embracing Randomness: The Stochastic Approach
Finally, we add the term "stochastic", which, in Greek, means “to aim at” or “to guess”. In our context, it introduces a bit of randomness into the algorithm. Traditional gradient descent looks at the entire dataset to decide the next step, which can be like trying to predict the weather by analyzing every day in history—it's thorough but immensely time-consuming.
Stochastic Gradient Descent randomly picks a few data points to estimate the gradient. It's like making weather predictions based on a random day in recent history. It is not perfect, but it is much faster and surprisingly effective. This approach allows the model to update more frequently and escape potential traps, like local minima — points that seem like the lowest but aren't really.
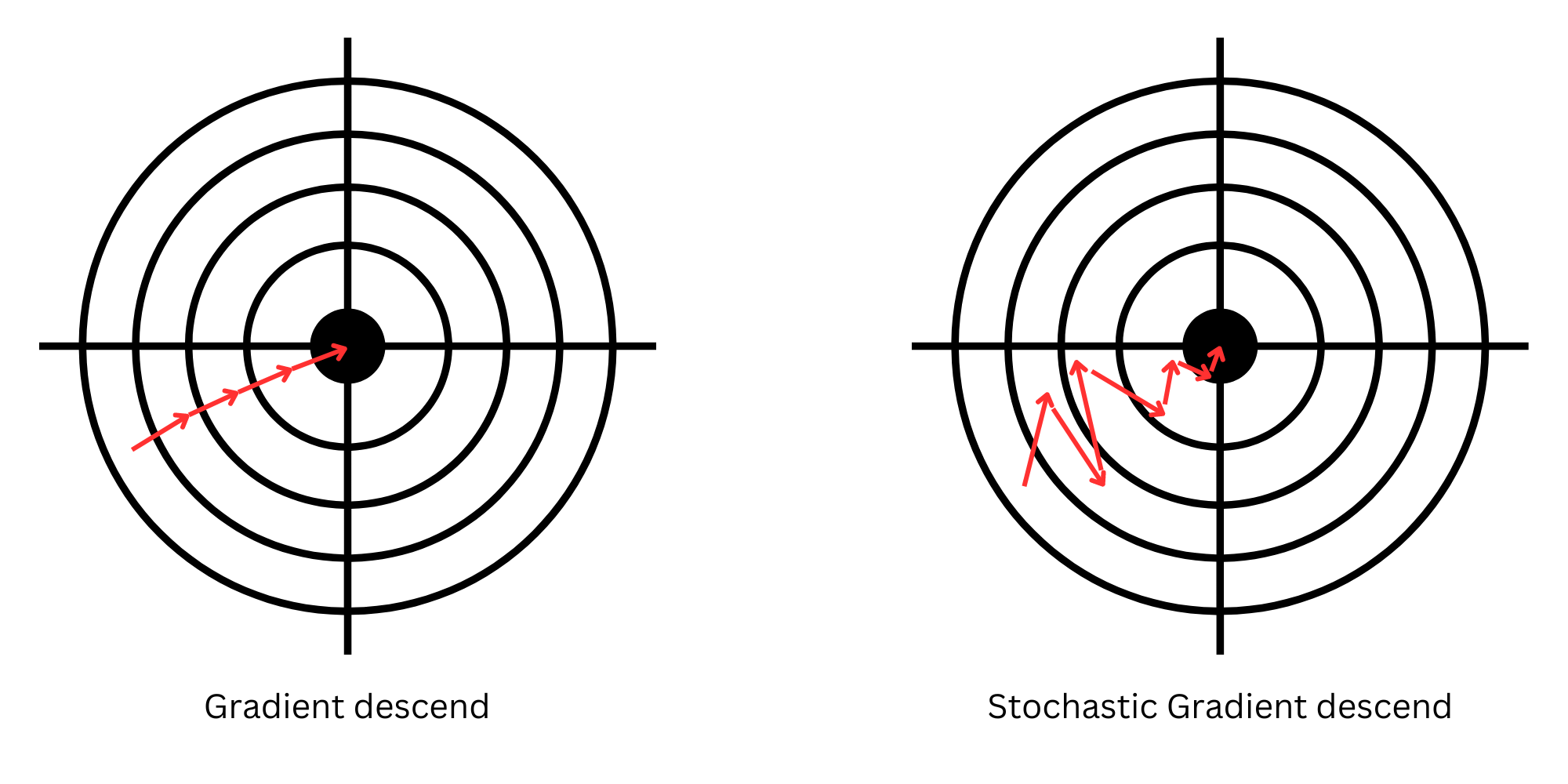
From the example above, you can see that the stochastic version took more steps, and those steps were not so precise on the way to the minimum. On the other hand, because much less data is processed for each step, the result is significantly faster and resource-efficient. This property is crucial for processing massive amounts of data for tasks such as processing or generating natural language or image recognition.
Mini-Batch Gradient Descent
Mini-Batch Gradient Descent is a variant of gradient descent that balances the robustness of the gradient descent (sometimes also called Batch Gradient Descent) and the efficiency and speed of SGD. Instead of using the entire dataset or a single sample to compute the gradient, Mini-Batch Gradient Descent uses a subset of the data, known as a "mini-batch," for each update. The main advantage is that this approach still maintains excellent computation efficiency, and at the same time, by averaging the gradient over a mini-batch, this method increases stability of each step leading to a smoother convergence.
By understanding the mechanics of SGD — gradients indicating the path, descent defining the learning, and stochastic adding a touch of randomness, we can appreciate guiding principles upon which modern machine learning evolves.
The next time you interact with a piece of AI, whether it's a voice assistant, a recommendation system, or a semi-autonomous vehicle, remember that there's a good chance that some version of gradient descent is working tirelessly behind the scenes, shaping the intelligence of machines, one random step at a time.
Top picks this week
Jordan Cutler - 5 Lessons I learned the hard way from 6 years as a software engineer
Practical Engineering Management - Top-down Leadership vs Center-out Leadership
Gergely Orosz - The end of 0% interest rates: what it means for software engineering practices
Let me know
If you enjoyed reading this article (I know I really enjoyed writing it), let me know what other topics you’d like to see in the “Demystifying AI” series.
In an upcoming issue, I want to cover Backpropagation — an algorithm for supervised learning of neural networks using gradient descent.
Also, don’t forget to share this post if you’ve found it helpful. I’ll really appreciate it :)